A Definitive Guide to Understanding LLMs (Large Language Models) for Beginners


If you’ve been curious about Large Language Models (LLMs), it’s best to start with the basics rather than jumping directly into technical jargon. LLMs are the powerhouse behind the current generative AI era, driving tools like ChatGPT, Dall-E, and Google Bard that have demonstrated impressive capabilities in generating human-like text.
These generative tools entirely rely on LLM technology to process data and generate accurate content according to the user’s prompt. Still wondering what LLMs are? Here’s an instance –
Think of a big library with endless book collections on different topics and subjects, each carrying countless amounts of information. That’s what the AI is all about. Now, LLMs work like librarians – digital curators with super abilities to not just provide information on each subject but also insightful answers.
Basically, LLMs aren’t a new term but one that has been revolutionizing the generative AI industry since its inception. However, one needs to understand that they aren’t just a topic but an entire concept with its own set of benefits, limitations, and real-world use cases. So, let’s start this beginner’s guide to understanding large language models (LLMs), how they work, and what the future holds for them.
LLM Statistics: An Overview of Current and Future Market
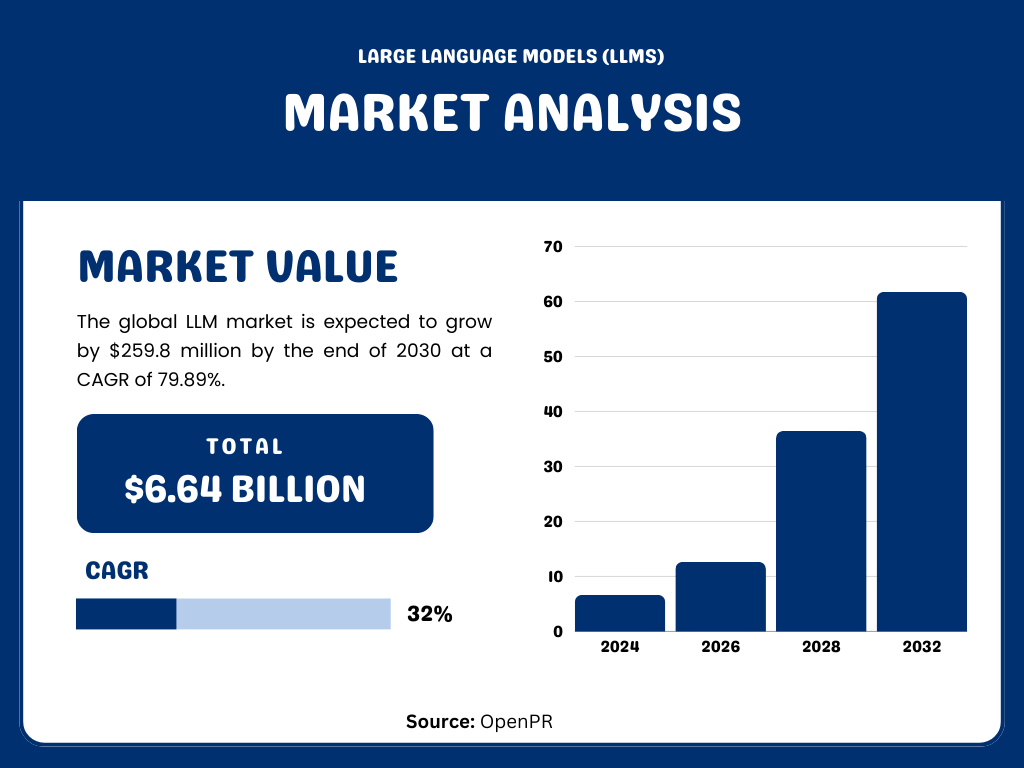
- The global LLM market is expected to grow by $61.74 billion by the End of 2030 at a CAGR of 32.1%. (Source: OpenPR)
- LLM is being adopted significantly in North America, with the US market expected to reach $105.54 million by 2030 at a CAGR of 72.1%. (Source: Pragma Research Market)
- By the End of 2025, the world’s top 5 LLM developers are expected to acquire 88.22% of the total market revenue. (Source: Pragma Research Market)
- It is predicted that 750 million apps will be using LLMs by the End of 2025. (Source: ERP Today)
- 50% of digital work will be automated by apps Using LLMs by 2025. (Source: ERP Today)
What are Large Language Models (LLMs)?
A Large Language Model (LLM) can be understood as an advanced AI program capable of executing a wide range of Natural Language Processing (NLP) tasks. These models, which are built on transformer architectures, are trained on extensive datasets, which is why they’re referred to as ‘large.’ This extensive training allows them to perform text recognition, translation, prediction, and generation tasks.
Often, these LLMs are also known as Neural Networks (NNs), computational models designed to mimic the human brain’s functioning. These networks operate using a layered network of nodes, similar to how neurons are arranged in the brain.
LLMs are not limited to learning human languages for AI applications. They can be trained to understand complex structures, such as writing software code. Much like the human brain, these models must be pre-trained and fine-tuned to solve problems related to text classification, answering questions, summarizing documents, and generating text.
The problem-solving abilities of LLMs find applications in various sectors like healthcare, finance, and entertainment. Here, they power a range of NLP applications, including translation services, chatbots, AI assistants, and more.
How Does Large Language Models (LLMs) Work?
LLMs work by using The Transformer Model structure that manipulates input via stages of encoding and decoding to yield a predicted output. However, before the LLM can accept text input and offer output predictions, it must undergo a training process to develop its general capabilities.
Here are the stages through which LLMs are trained:
Pre-Training Phase
Large Language Models are pre-trained using extensive text datasets that include diverse data such as books, articles, and websites. These datasets, which consist of trillions of words, significantly impact the model’s performance.
During this phase, the LLM engages in unsupervised learning from all the supplied datasets without any specific direction. The pre-training phase is the most resource-intensive and time-consuming stage of building a LLM. In this stage, LLMs learn not only to comprehend various words, their meanings, and the relationships among them but also the context in which these words are used.
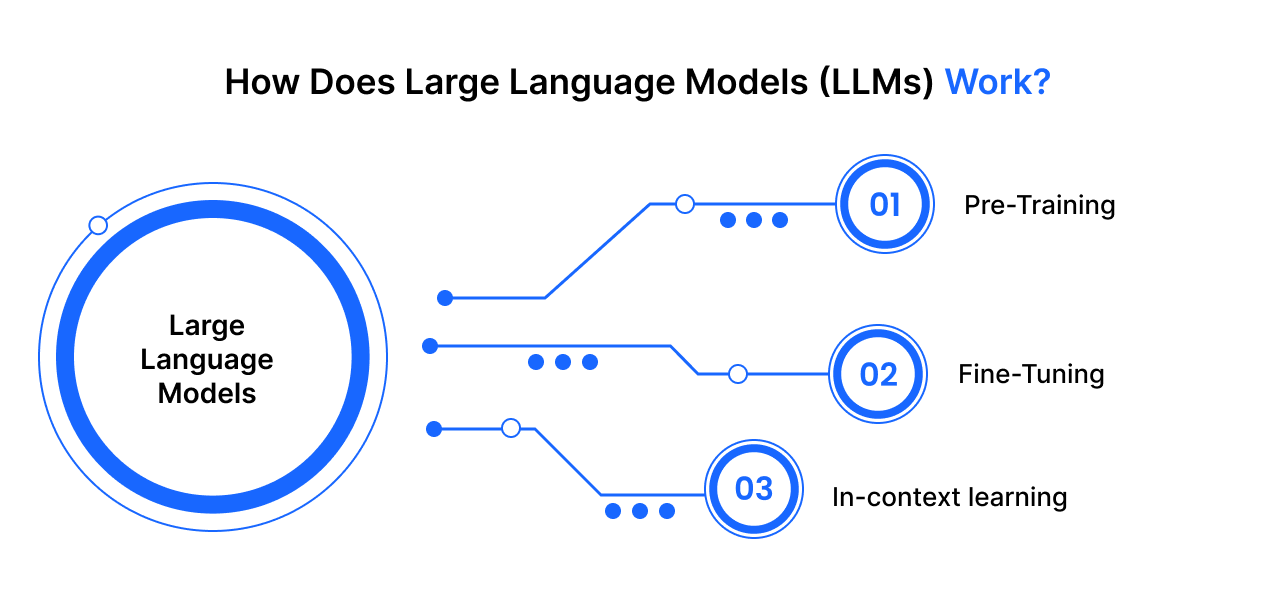
Fine-Tuning
While pre-existing models are impressive, they aren’t naturally specialized in performing specific tasks. The process of refining a Large Language Model (LLM) involves training the pre-existing model to excel at a specific task.
This could be sentiment analysis, language translation, or answering questions in a particular field. This method allows LLMs to express their capabilities and fully adapt them to specific uses.
In-context learning and Prompt Tuning
In-context learning is the process of learning and adapting from the context of an ongoing conversation or interaction. On the other hand, prompt tuning involves modifying and training the model with specific prompts or instructions to enhance its performance in certain tasks or contexts. This makes the model more efficient and effective in handling particular tasks.
Understanding the Different Types of Large Language Models (LLMs)
There are 5 major types of Large Language Models, each with its distinct advantages and disadvantages. Understanding each type will help you grasp the concept of LLMs easily.
Autoencoder-Based Models
These models transform the input text into a more compact form and then create new text from this condensed form. They excel in tasks like condensing text or creating content.
Sequence-to-Sequence Models
This type of model takes a sequence (like a sentence) as input and produces another sequence (like a translation) as output. They are commonly used for tasks like machine translation and text condensation.
Transformer-Based Models
These models use a type of neural network structure that excels at recognizing long-term dependencies in text data. They are versatile and can be used for various language tasks, including text generation, language translation, and question-answering.
Recursive Neural Network Models
These models are tailored to process structured data, such as parse trees, which depict the grammatical structure of a sentence. They are handy for tasks like sentiment analysis and natural language inference.
Hierarchical Models
These models are designed to process text at varying levels of detail, such as sentences, paragraphs, and entire documents. They are used for tasks like document categorization and topic modeling.
What is Large Model Language (LLM) Used for?
Large language models (LLMs) are versatile tools with a wide range of industrial applications across numerous fields and sectors. Here are some of the most prevalent uses:
Content Creation
One of the primary capabilities of LLMs is generating text. They can produce relevant and meaningful content in a sequential manner, which can be utilized for creating content for blogs, websites, brochures, and more.
They can also fill in gaps in documents where information is missing. Moreover, these models can be tailored to generate content specific to various domains, making them flexible and adaptable to different industries.
Summarizing Content
LLMs can sort large amounts of information, identify the key points, and present them in a summarized form. This feature of LLMs is particularly useful in sectors like law, healthcare, and finance, where sifting through vast amounts of data can be time-consuming.
Researchers can use this feature to stay abreast of the latest information and gain a broad understanding of their field in a time-efficient manner.

Sentiment Analysis
To understand the emotional context or mood conveyed by a user, these language models employ a technique known as sentiment analysis.
This method involves the model scrutinizing the text and categorizing the expressed sentiment as positive, negative, or neutral. This feature is particularly useful for businesses when interpreting their customer feedback.
Chatbots and AI Conversations
Advanced language models have the ability to generate text that closely resembles human conversation, which is particularly appealing in interactive scenarios.
For instance, a chatbot can respond to a user’s specific query or request. These customer service chatbots streamline the process and provide the necessary information to the user. This technology can also be extended to develop virtual assistants, educational resources, and more.
Code Generation
Large Language Models (LLMs) can support developers in various tasks, such as mobile app development, identifying code errors, and detecting security vulnerabilities across multiple programming languages. They can even “translate” between different programming languages.
Advantages of Large Language Models (LLMs)
Large Language Models (LLMs), such as ChatGPT, have shown tremendous promise for businesses. In fact, ChatGPT’s rapid growth since its launch has set a record in the digital application world. As these models become more common, their applications across various sectors and industries are expected to grow.
Here are some of the advantages of using LLMs:
Creating Content
As said, the powerful force behind generative AI is LLMs that excel at creating content. They can generate text and, when combined with other models, images, videos, and audio. Depending on the data used to fine-tune them, the content they produce can be tailored to specific sectors like law, finance, healthcare, and marketing.

Improving Natural Language Processing (NLP) Tasks
LLMs have shown exceptional performance in many NLP tasks. They can understand and interact with human language with remarkable accuracy. However, it’s worth noting that these models could be more flawless and can sometimes produce inaccurate results or even create information that doesn’t exist.
Boosting Efficiency
One of the leading business benefits of LLMs is their ability to complete mundane, time-consuming tasks quickly. This efficiency can be a game-changer for companies, but it also raises important questions about the impact on workers and the job market. These considerations need to be addressed as we continue to adopt and integrate these models into our work processes.
Limitations and Challenges of Large Language Models (LLMs)
Large language models (LLMs) may seem to comprehend and accurately respond to meaning, but it’s crucial to remember that they are merely technological instruments.
They may encounter a range of issues, including:
Misinterpretations
Sometimes, an LLM might generate an output that is incorrect or doesn’t align with the user’s intention. This is known as a “misinterpretation.” For instance, it can occur when the LLM asserts that it’s a human, possesses feelings, or is romantically attracted to the user. Since LLMs predict the next grammatically correct word or phrase, they need help to grasp human meaning fully, leading to these misinterpretations.
Security Concerns
If not properly monitored or controlled, LLMs can pose significant security threats. They have the potential to disclose individuals’ confidential data, engage in phishing attacks, and generate spam.
Malicious users can manipulate AI to reflect their ideologies or biases, facilitating the dissemination of false information. The global implications of such actions can be catastrophic.
Despite their impressive capabilities, LLMs are tools and should be treated as such, with an understanding of their limitations and potential risks.
Bias
The outputs of large language models (LLMs) are influenced by the Data used for their training. If this data is skewed towards a particular demographic or lacks diversity, the LLM’s outputs will reflect this lack of diversity.
Consent Issues
LLMs are trained on vast amounts of data, some of which may not have been acquired with consent. These models can scrape data from the internet, often disregarding copyright licenses, plagiarizing content, and repurposing proprietary content without the original owners’ or artists’ permission.
When results are produced, it’s impossible to trace the data’s origin, and creators are often not credited. This can expose users to potential copyright infringement issues.
Moreover, LLMs may scrape personal data, such as names of subjects or photographers, from photo descriptions, posing a threat to privacy. LLMs have faced lawsuits, including a notable one by Getty Images, for intellectual property violations.
Deployment and Scaling Challenges
The deployment of LLMs involves deep learning, transformer models, distributed software and hardware, and a high level of technical expertise. Simultaneously, scaling and maintaining LLMs can be challenging, time-consuming, and resource-intensive.
Examples of Popular Large Language Models (LLMs)
Large language models (LLMs) have become a global sensation, finding applications in various sectors. One such well-known generative AI chatbot is ChatGPT.
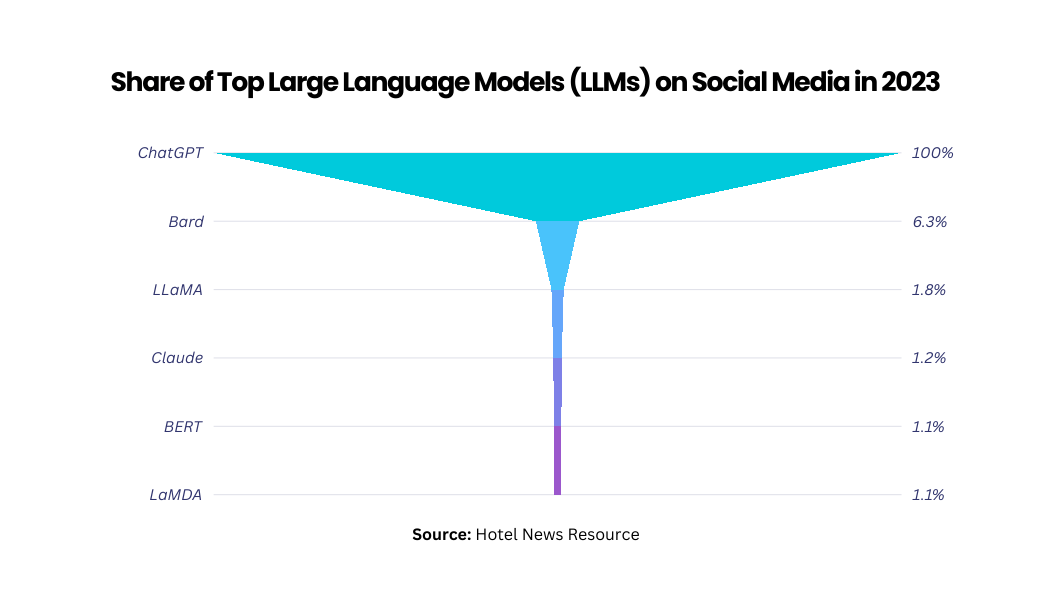
Apart from this, there are many more examples, including –
PaLM
This is Google’s Pathways Language Model. It’s a transformer language model that excels in tasks like common-sense and arithmetic reasoning, explaining jokes, generating code, and translating languages.
BERT
Also, a Google brainchild, the Bidirectional Encoder Representations from Transformers (BERT), is a transformer-based model. It’s known for its proficiency in understanding natural language and answering queries.
XLNet
XLNet is a permutation language model that stands out from BERT by generating Output predictions in random order. It evaluates the pattern of encoded tokens and predicts tokens in a random sequence, not in a linear one.
GPT
The Generative Pre-trained Transformers, developed by OpenAI, are perhaps the most recognized large language models. GPT, with its various iterations (like GPT-3, GPT-4, etc.), has been fine-tuned to perform specific downstream tasks.
For instance, Salesforce’s EinsteinGPT is used for CRM, and Bloomberg’s BloombergGPT is employed in finance. These models are enhancements of their previous versions.
LLMs vs Generative AI: Are They Same?
Large Language Models (LLMs) and Generative AI are both crucial components of artificial intelligence technology, each with its own unique role.
LLMs, including models like GPT-3, BERT, and RoBERTa, are explicitly designed for understanding and generating human language, making them a part of the broader Generative AI field.
On the other hand, Generative AI is a broader term that includes a variety of models capable of producing a wide range of content, from text and images to music and beyond.
Interestingly, LLMs have evolved to become multimodal, meaning they can handle and generate content across multiple formats, such as text, images, and code. This evolution marks a significant milestone in LLM technology, expanding their capabilities and enhancing their interaction with the world. Multimodal LLMs like GPT-4V, Kosmos-2.5, and PaLM-E are still in the development stages, but they promise to transform our interaction with computers.
One way to differentiate between generative AI and LLMs is to view generative AI as an objective, while LLMs are a means to achieve that objective. It’s important to note that while LLMs are a potent tool for content generation, they are not the only route to achieving generative AI.
Other models, such as Generative Adversarial Networks (GANs) for images, Recurrent Neural Networks (RNNs) for music, and specialized neural architectures for code generation, are designed to produce content in their respective fields.
In the end, LLMs and Generative AI are not the same. While not all generative AI tools are based on LLMs, LLMs themselves are a type of generative AI.

What’s Next for LLMs?
The future of large language models (LLMs) is indeed promising for various sectors and industries. Moreover, they are continuously improving, enhancing their ability to comprehend and respond to human language. In the near future, their efficiency will reach a level where they can be utilized on a wide range of devices, from smartphones to compact gadgets.
What’s more, these LLMs will specialize in various fields, such as healthcare or legal matters, providing expert assistance. But their capabilities won’t be limited to text. They’ll be able to process images and sounds, and they’ll be compatible with numerous languages globally.
Efforts are being made to ensure these AI models operate fairly and accountable, reducing bias and promoting transparency. In essence, these LLMs are set to become invaluable allies, aiding us in a multitude of tasks and simplifying our lives in numerous ways. Their potential is genuinely remarkable.
Conclusion
The role of Large Language Models (LLMs) has been significant in an ongoing buzz of generative AI. Moreover, their potential uses are so extensive that they’re expected to impact every field, including data science. The opportunities they present are limitless, but they also come with their own set of risks and challenges.
With their transformative potential, LLMs have ignited discussions about the future, particularly how AI will influence employment and various other societal aspects.
Given the high stakes, this is a crucial concern requiring a collective and resolute approach. The future of AI and its implications warrants our attention and thoughtful deliberation. So, what are your thoughts on LLMs and generative AI?
FAQs
What are LLMs in AI?
Large Language Models (LLMs) are advanced AI systems capable of understanding and generating human-like text. They process vast amounts of data to learn language patterns and nuances.
What does LLM Stand for in ChatGPT?
In ChatGPT, LLM stands for Large Language Model. It’s the underlying technology enabling the chatbot to generate responses that mimic human conversation.
What is LLM and GPT?
LLM is a broad category of AI models that includes GPT (Generative Pretrained Transformer). GPT is a specific type of LLM known for its ability to generate coherent and contextually relevant text.
Is There a Better LLM than ChatGPT?
AI technology is rapidly evolving, and newer LLMs may have different capabilities. However, “better” can be subjective and depends on the specific application or task.
Is LLM a Generative AI?
Yes, LLM is a type of Generative AI. It generates new content based on the input it receives, often creating text that’s indistinguishable from that written by humans.
Is LLM Part of NLP?
LLM is part of Natural Language Processing (NLP), an AI field focused on the interaction between computers and human language. LLMs are pivotal in understanding and generating human language.